
Ever wondered how a Machine Learns?
Understanding Machine Learning: From Supervised Learning to Inference
Machine Learning systems are designed to learn from data inputs, allowing them to make predictions on never-before-seen data based on patterns learned from known data.
Supervised Learning: The Foundation
The majority of Machine Learning techniques fall under the category of Supervised Learning. In Supervised Learning, the system is trained on a labeled dataset, where the desired outputs (labels) are provided along with the input data (features). This training process enables the machine to learn the relationship between the features and the labels.
For example, consider a task of predicting housing prices based on historical data. The labels would be the actual housing prices, while the features could include factors such as the size of the house, the number of bedrooms, the location, and other relevant attributes. By analyzing the patterns in the training data, the machine learning model learns to map the features to the corresponding labels (housing prices).
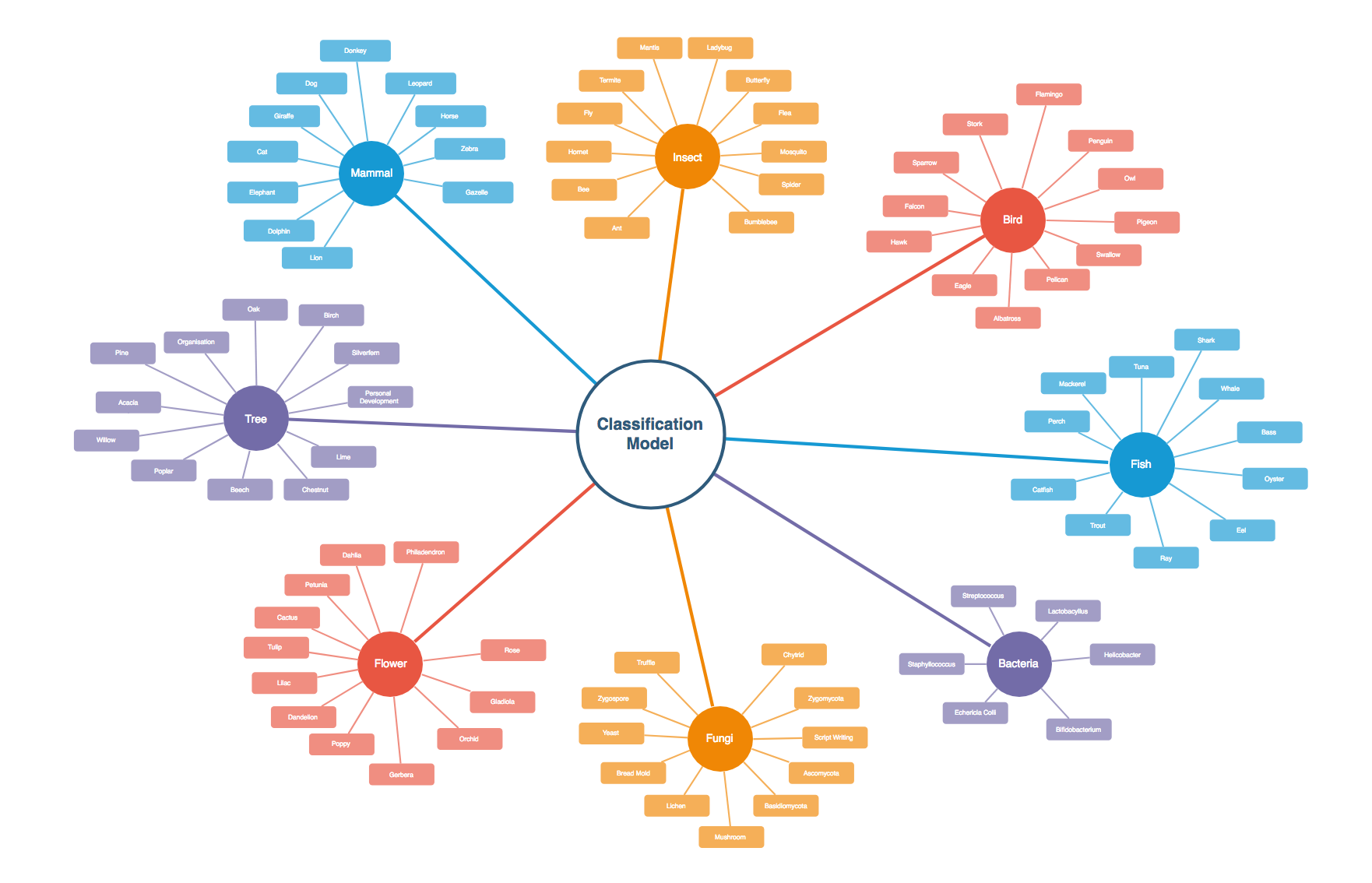
Classification vs Regression
Machine Learning models can be broadly categorized into two types: Classification and Regression models.
Classification Models are used to predict discrete values or categories. A classic example is image classification, where the model learns to identify and classify objects in images, such as distinguishing between cars, trucks, and vans. These models assign input data to one of several predefined classes or categories.
A Regression Model on the other hand, are used to predict continuous numerical values. The housing price prediction example mentioned earlier is a regression problem, where the model aims to predict a numeric value (price) based on the input features. Other examples of regression problems include predicting stock prices, predicting energy consumption, or forecasting sales figures.
Labels and Features
In both classification and regression problems, the labels represent the target variable that the model aims to predict. The features, or input variables, are the factors that the model uses to make its predictions.
Using the spam email classification example, the labels could be “Spam” or “Not Spam,” while the features could include characteristics of the email, such as the subject line, the sender’s address, the presence of certain keywords, or the email content itself.
Training the Model
To train a machine learning model, labeled examples are used to define the relationship between the features and the labels. This process involves feeding the labeled data into the model and adjusting its internal parameters to minimize the difference between the model’s predictions and the actual labels.
The training process may go through multiple iterations, with the model’s performance being evaluated and refined at each step. This tuning process helps improve the model’s accuracy and generalization capabilities.
Inference: Making Predictions
Once a model has been trained on labeled data, it can be used to make predictions on unlabeled data through a process called inference. During inference, the model takes the input features of new, unseen data and applies the learned patterns to generate predictions or classifications.
For example, a trained spam email classification model can analyze the features of a new, unlabeled email and predict whether it is likely to be spam or not, based on the patterns it learned during the training phase.
Beyond the Basics
While this blog post covers the fundamental concepts of Machine Learning, it’s important to note that the field encompasses a wide range of algorithms, techniques, and considerations.
Different algorithms, such as decision trees, support vector machines, neural networks, and ensemble methods, have their own strengths and weaknesses, making them suitable for different types of problems and data structures.
Additionally, data preprocessing and feature engineering play crucial roles in the success of machine learning models. Careful selection, transformation, and extraction of relevant features can significantly improve model performance.
Machine Learning is a vast and continuously evolving field, with new developments and advancements happening all the time. However, understanding the core concepts of supervised learning, classification, regression, labels, features, training, and inference is a solid foundation for further exploration and application of these powerful techniques.