
Type i and Type ii errors
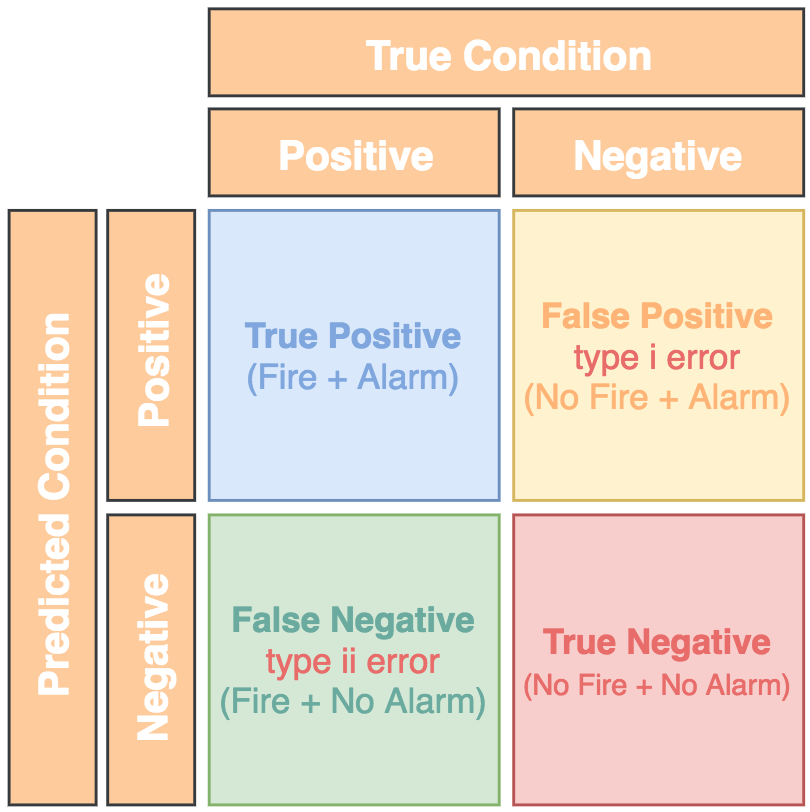
A type i error might be when your home smoke detector is triggered by burning toast, this detector is primarily there to wake you up if there’s a fire in your home, so a false positive in this scenario is that the alarm is sounding, but your home is not on fire. The false negative state would be far more serious in that your house is on fire but your smoke detector has not detected the event.
We can further expand on the smoke detector analogy by suggesting that there are 2 states of truth or two ground truths. a ground truth is a state that meets the design specifications of the model, or in this case, the smoke detector, a True Positive and a True Negative.
Truth 1 = There is no fire and the smoke detector is silent Truth 2 = There is a fire and the smoke detector is producing an audible (and perhaps visual) alert
When defining a model, we might want to consider what rate of error we would accept, and again, in the case of the smoke detector or a car alarm, we’d like it to be more sensitive, we’d happily take some false alarms in hoping that the sensitivity will be the thing that ensures our alarm wakes us if there is a fire, or alerts us that someone is trying to steal the car.
Understanding the types of errors you’re willing to accept in your model and at what frequency allows your model to have some flexibility and allows for some anomalies to occur without destroying the predictability of the output.