
Support Vector Machines
An SVM is one of a set of algorithms called Kernel Methods. Kernel methods are a a set of classification algorithms that aim to solve classification problems by using decision boundaries.
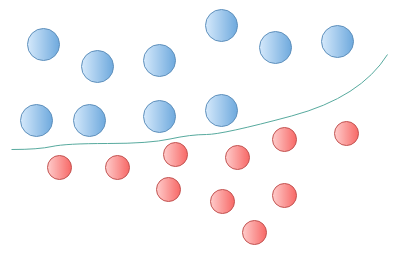
A Decision Boundary is a line (Hyperplane) that might be drawn to separate to classes of observed data. New data points are considered against the line in order to check which side they fall. The better the hyperplane, the further the data point is from the hyperplane (maximising the margin).
This approach allowed samples beyond the training set to generally fall on the right side of the hyperplane. Back in the early 1990’s when SVM’s were receiving lots of attention, it was identified that they were relatively efficient at solving simple classification problems.
Further to the success seen in simple classification, SVM’s were relatively simple to implement and to understand, driving lots of take up and ultimately helping to generate false promise. As data sets increased it became clear that SVM’s do not scale well, equally, they were essentially useless at perceptual problems like image classification for example.
Support Vector Machines required something called feature engineering which was a manual process whereby a human would need to make useful and meaningful representations before the SVM could be let loose. The process of feature engineering could be time consuming, generally difficult and brittle.