
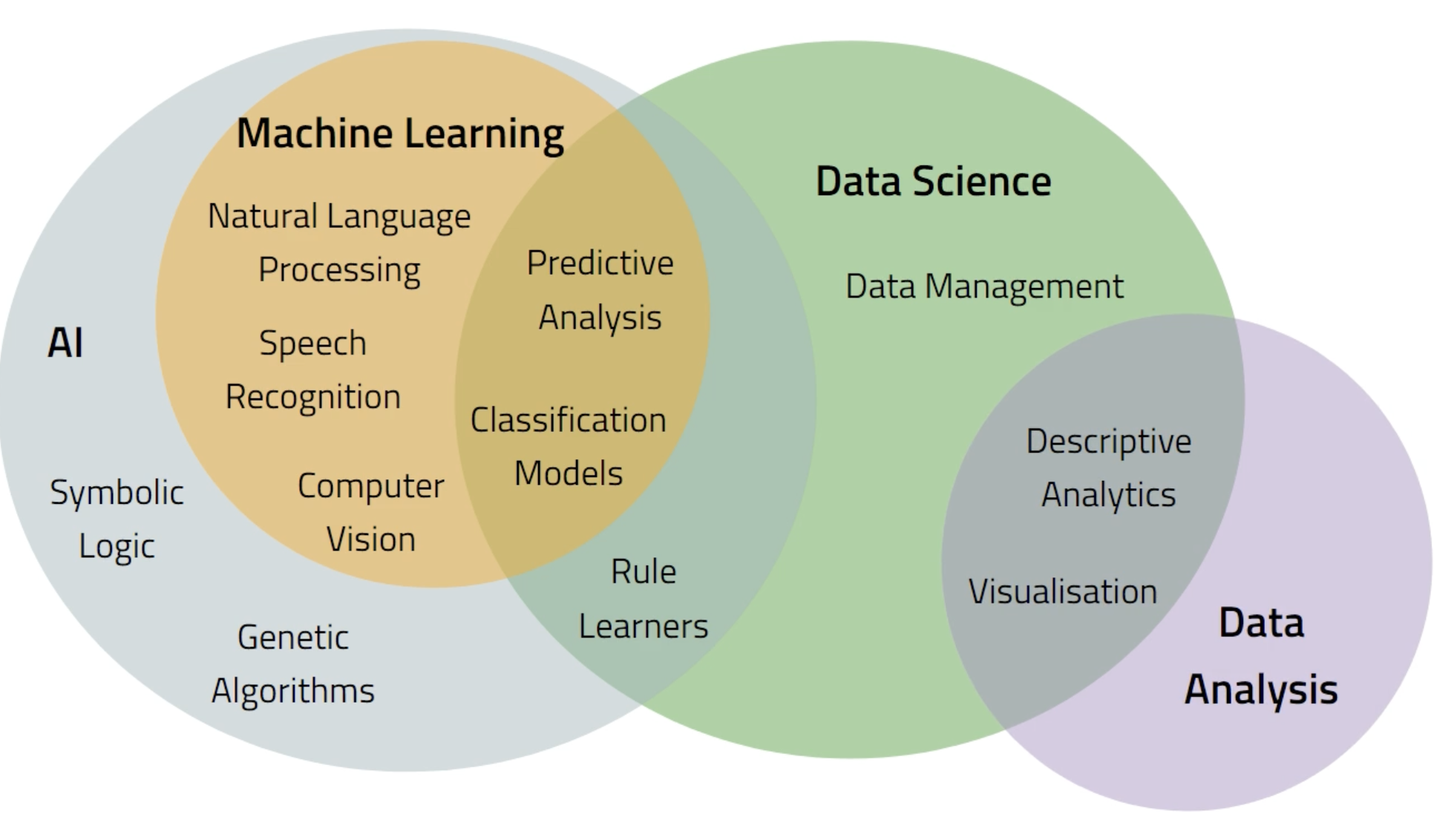
Exploratory Data Analysis
Always look at your data
It is important to always look at the data before you do anything, a good old Eyeball mark 1.0 can give you a lot. Now of course we know that when it comes to analysing large volumes of data, nothing will beat a machine, but it is quite amazing just how much you can get from just looking at the data.
If you can’t see the data, then don’t believe it, always be a data skeptic.
Exploratory Data Analysis (EDA)
Once we’ve seen the data, we want to start exploring the data. This is where we look for simple distributions and relationships, start looking for errors etc. That eyeball check was worth doing, but we’re usually dealing with vast quantities of data and we’ll soon need the machine to help us dig in. EDA allows us to visualise distributions and relationships. We can detect errors (simple things like NaN for example), we may be able to start assessing our assumptions.
The primary purpose of EDA is to reveal the underlying structure(s) of the data.
We want to look for insights, we’re looking for critical impact variables that might influence the dataset and look for outliers.
Critical Impact Variables
Critical impact variables are the variables that have a significant influence on the analysis outcomes or results. The identification of critical impact variables is fundamental for effective data analysis and modeling.
Dependent Variable
The dependent variable is the variable that is being predicted or explained by other variables. It is the outcome or response variable of interest. Identifying the dependent variable is essential for understanding the main focus of the analysis and determining the appropriate modeling techniques.
Independent Variables
Conversely independent variables, also known as predictor variables or features, they are the variables that are used to predict or explain the dependent variable. These variables can have a direct or indirect impact on the outcome. Selecting the most relevant independent variables is crucial for building accurate models and identifying significant relationships.
Control Variables (covariates)
Covariates are variables that are included in the analysis to account for potential confounding or extraneous factors. They help isolate the relationship between the independent and dependent variables by holding certain variables constant. Identifying appropriate control variables is essential for understanding potential biases or alternative explanations.
Domain Knowledge is key!
It is important to note that the identification of critical impact variables in data analysis often requires a combination of domain expertise and EDA.
I’m preparing a follow-up post on this content as I’d like to look at some different types of non-graphical EDA such as Skewnewss and Central Tendency as well as some graphical EDA like Boxplots.